CQRS vs. OOP a Pomodoro throw down
October 27, 2016
Design data models for the Pomodoro Technique, one for CQRS and one for OOP and show how the CQRS model is simpler and more flexible.

Software products, services or line-of-business systems which need to store data can be built using an event log as the source of truth instead of relying on “traditional” databases.
Introduction to the Pomodoro Technique
The Pomodoro Technique improves your productivity by having you
- work on one thing for 25 minutes straight,
- become better at estimating time for a task, and
- taking a five-minute breaks every half hour to let your mind rest
I have been using this for the past two weeks, and have found that if I am able to maintain discipline, it is remarkably effective and that I am getting more done, feeling more satisfied at work, and becoming a better estimator.
User Stories
All of these stories are for a single user, the worker.
- At the start of my work day I create a TO DO list for the day so that I work on the most important tasks first.
- During a pomodoro, I must work on one thing and one thing only so that I become more productive.
- When a pomodoro is done, I need to take a five minute break and cross off one of my estimated pomodoros for that task.
- When I complete four pomodoros, I need to take a 15-minute break so that I can start the next task with vigor.
- I need to estimate the number of “pomodoros” (25-minute chunks) each task will take so that I can record how accurate my estimates are.
- During a pomodoro, I need to record interruptions so that I can learn how much they affect my work day.
- If I cross off all of my estimated blocks of time, and there is still work to do, I need to re-estimate the time left on that task.
- I need to maintain a master TO DO list (an inventory) so when I think of something else to do, I can record it there.
- At the end of the day, I need to summarize my day and add to a daily record by recording the number of:
- pomodoros completed
- interruptions, by type (internal and external)
- tasks, by type (planned and unplanned)
- hours worked
- tasks that were underestimated
- total pomodoros (for completed tasks) that were not required (total over estimated)
OOP Data Model
An object-oriented design focuses on the nouns in the system, since those are thought to be the more stable entities in the system. The idea is that by modeling the stable entities, the software will require less change as the system evolves.
Pulling the major nouns out of the use cases above, we get
- task
- pomodoro
- interruption
- estimate
- break
- daily TODO list
- master TODO inventory
- daily record
The nouns pomodoro, estimate, break are value objects A value object has no identity or life cycle. and are modeled as attributes and not entities. The inventory and record nouns are views over the task and workday entity sets Task and WorkDay and relationship set WorksOn.
OOP Entity-Relationship Diagram
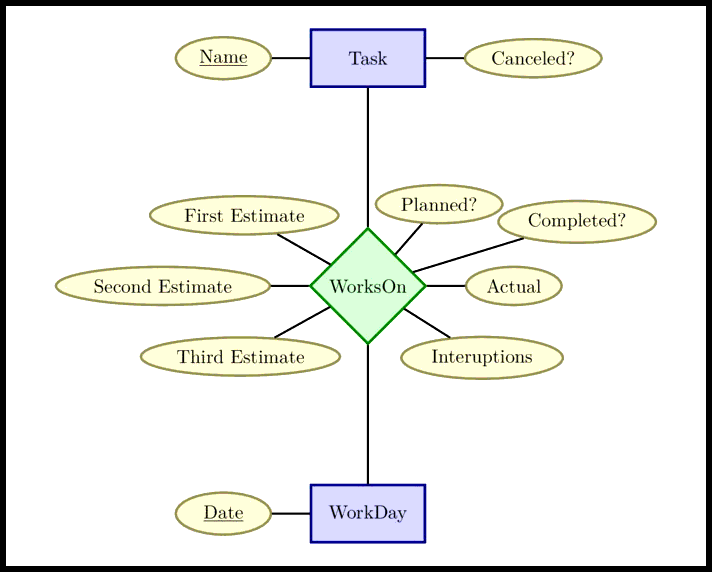
OOP SQL
Here is the SQL All SQL in this blog entry was tested with SQLite. that implements this model.
PRAGMA foreign_keys = ON
;
DROP TABLE IF EXISTS workson
;
DROP TABLE IF EXISTS task
;
DROP TABLE IF EXISTS workday
;
CREATE TABLE task(
name TEXT PRIMARY KEY,
canceled TEXT NOT NULL CHECK (canceled IN (’Y’, ’N’)) DEFAULT ’N’
)
;
CREATE TABLE workday(
date TEXT PRIMARY KEY
)
;
CREATE TABLE workson(
task_name TEXT NOT NULL REFERENCES task (name) ON UPDATE CASCADE,
date TEXT NOT NULL REFERENCES workday (date) ON UPDATE CASCADE,
first_estimate INTEGER NOT NULL CHECK (first_estimate > 0),
planned TEXT NOT NULL CHECK (planned IN (’Y’, ’N’)) DEFAULT ’Y’,
interruptions INTEGER NOT NULL CHECK (interruptions >= 0) DEFAULT 0,
completed TEXT NOT NULL CHECK (completed IN (’Y’, ’N’)) DEFAULT ’N’,
second_estimate INTEGER CHECK (second_estimate > 0),
third_estimate INTEGER CHECK (third_estimate IS NULL
OR (second_estimate IS NOT NULL
AND third_estimate > 0)),
actual INTEGER CHECK (actual > 0),
PRIMARY KEY(task_name, date)
)
;
DROP VIEW IF EXISTS record
;
CREATE VIEW record AS
WITH actuals
AS (
SELECT date
, sum(actual) n
, sum(interruptions) int
FROM workson
GROUP BY date),
planned
AS (
SELECT date, count(*) n
FROM workson
WHERE planned = ’Y’
GROUP BY date),
unplanned
AS (
SELECT date, count(*) n
FROM workson
WHERE planned = ’N’
GROUP BY date),
completed
AS (
SELECT date, count(*) n
FROM workson
WHERE completed = ’Y’
GROUP BY date),
under
AS (
SELECT date, count(*) n
FROM workson
WHERE second_estimate IS NOT NULL
GROUP BY date),
over
AS (
SELECT date
, SUM(first_estimate) - sum(actual) n
FROM workson
WHERE completed = ’Y’
AND first_estimate > actual
GROUP BY date)
SELECT workday.date
, IFNULL(actuals.n, 0) AS pomodoros
, IFNULL(actuals.int, 0) AS interruptions
, IFNULL(planned.n, 0) AS planned_tasks
, IFNULL(unplanned.n, 0) AS unplanned_tasks
, IFNULL(under.n, 0) AS under_estimated_tasks
, IFNULL(over.n, 0) AS total_over_estimate
FROM workday
LEFT OUTER JOIN actuals ON actuals.date = workday.date
LEFT OUTER JOIN planned ON planned.date = workday.date
LEFT OUTER JOIN unplanned ON unplanned.date = workday.date
LEFT OUTER JOIN under ON under.date = workday.date
LEFT OUTER JOIN over ON over.date = workday.date
;
DROP VIEW IF EXISTS inventory
;
CREATE VIEW inventory AS
SELECT name
FROM task
WHERE name NOT IN (SELECT DISTINCT task_name
FROM workson
WHERE completed = ’Y’)
AND canceled = ’N’
;
CQRS Data Model
In CQRS, we model by looking for:
things that happen that lead to some kind of new information in the domain. We map these happenings to a set of events. Since events are about things that have taken place, they are named in the past tense.
Re-reading through the use cases above, you can pull out the following actions:
The Actions
- TaskAdded
- TaskEstimated
- TaskInterrupted
- TaskDone
- PomodoroStarted
- PomodoroDone
- WorkDayDone
CQRS Entity-Relationship Diagram
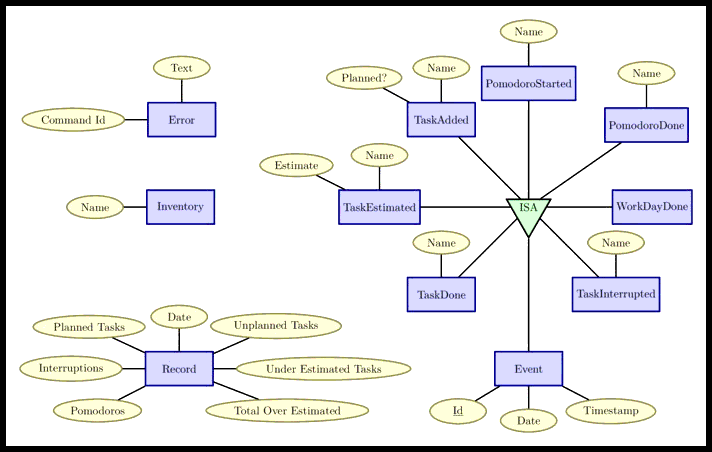
CQRS SQL
PRAGMA foreign_keys = ON
;
DROP TABLE IF EXISTS task_added
;
DROP TABLE IF EXISTS task_estimated
;
DROP TABLE IF EXISTS task_done
;
DROP TABLE IF EXISTS pomodoro_started
;
DROP TABLE IF EXISTS pomodoro_done
;
DROP TABLE IF EXISTS work_day_done
;
DROP TABLE IF EXISTS event
;
DROP TABLE IF EXISTS inventory
;
DROP TABLE IF EXISTS record
;
DROP TABLE IF EXISTS error
;
CREATE TABLE event(
id INTEGER PRIMARY KEY,
date TEXT NOT NULL,
-- current_timestamp is in UTC timezone
timestamp DATETIME NOT NULL DEFAULT current_timestamp,
type TEXT NOT NULL
)
;
CREATE TABLE task_added(
event_id INTEGER NOT NULL REFERENCES event (id),
task_name TEXT NOT NULL,
planned TEXT NOT NULL CHECK (planned IN (’Y’, ’N’)) DEFAULT ’Y’
)
;
CREATE TABLE task_estimated(
event_id INTEGER NOT NULL REFERENCES event (id),
task_name TEXT NOT NULL,
estimate INTEGER NOT NULL CHECK (estimate > 0)
)
;
CREATE TABLE task_done(
event_id INTEGER NOT NULL REFERENCES event (id),
task_name TEXT NOT NULL
)
;
CREATE TABLE pomodoro_started(
event_id INTEGER NOT NULL REFERENCES event (id),
task_name TEXT NOT NULL
)
;
CREATE TABLE pomodoro_done(
event_id INTEGER NOT NULL REFERENCES event (id),
task_name TEXT NOT NULL
)
;
CREATE TABLE work_day_done(
event_id INTEGER NOT NULL REFERENCES event (id)
)
;
CREATE TABLE record(
date TEXT NOT NULL,
pomodoros INTEGER,
interruptions INTEGER,
planned_tasks INTEGER NOT NULL CHECK (planned_tasks > 0),
unplanned_tasks INTEGER,
under_estimated_tasks INTEGER,
total_over_estimate INTEGER
)
;
CREATE TABLE inventory(
task_name TEXT NOT NULL
)
;
CREATE TABLE error(
command_id INTEGER NOT NULL,
text TEXT NOT NULL
)
;
The OOP and CQRS models are equivalent sources of truth.
While extremely different in structure, the two data models support the user stories.
Some observations of the differences between the two models:
CQRS
- puts all business logic in commands and read models,
- has one table for each event type, and
- keeps a strong decoupling between each database table
OOP
- has fewer tables,
- encodes business logic in the form of foreign keys and check constraints, and
- has complex views that generate the reports.
Overall, I find the CQRS model simpler because, although there are more tables, the tables are decoupled and there is no complex views.
How do the models handle change?
Consider a few ways the system might change over time—how does each data model cope with the change?
Change pomodoro size from 25 minutes to 50 minutes.
OOP: No change required.
CQRS: No change required. Since we store start and end event of each pomodoro, the pomodoro duration data is stored in the event history and could be used in a read-model, if required.
Winner: CQRS.
Differentiate between external and internal interruptions.
OOP: Add two new fields internal_interruptions and external_interruptions. Make existing field represent the total of those two. Unclear how to migrate old records.
CQRS: Add a new event type TaskInterrupted_v2 that has a second attribute ’Internal?’. Add same two new fields to record table. Also unclear how to report on old and new records.
Winner: Tie.
Add the ability to group small tasks into one pomodoro.
Some tasks do not take 25 minutes. In the Pomodoro method, you would group a few of these smaller tasks together and then make an estimate for the group.
Also, these groupings can vary from day-to-day. For example, if you group four of them on day one, but only complete three of them, the one unfinished one could be grouped with a different set of small tasks on day two.
OOP:
The best way forward here was not clear to me. Here is one approach that should work.
- new table Group
- with fields id and task_name
- unique key on (id, task_name)
- task_name is foreign key to task.name.
- WorksOn
- new field group_id that is nullable and is a foreign key to Group.id
- Make task_name nullable
- add constraint that either task_name or group_id must be non-null
- add constraint that only one of task_name or group_id can be non-null
- delete primary key
- make unique key on (date, task_name, group_id)
CQRS: Add a new event TaskAddedToGroup with two attributes: group_name and task_name. When adding a group, use the existing AddTask command with the group name.
Winner: CQRS.
Summary
With CQRS you get a simpler data model that is more flexible to change.
But … this is just the data model side. To be a true comparison, we need to compare the code as well.
Resources
- Database System Concepts, Sixth Edition, 2010, by Avi Silberschatz, Henry F. Korth, S. Sudarshan.
- Power Point slides for Database Design: The Entity-Relationship Approach section from Part 2 of the above book.
- The Tikz-er2 Package, Pável Calado
- Edument CQRS Tutorial, Part 1: Design.